按照上文讲到,我们已经抓取到了所有与“伯明翰大学”相关的数据,我们接下来要做的就是做数据清洗工作。

我们当前进度:2
- 爬虫程序——抓取全百度百科与“伯明翰大学”相关的数据
- 数据去重——用pandas去掉抓取相同的URL或相同的名称
- 提取人名——利用HMM-Viterbi进行人名筛选与提取
- 下载器——下载所有数据库中数据清洗过的URL,并存入数据库
- 人物Ranking——按照一定的排名方式,对人物进行知名度排名
- 人物梗概——利用NLP相关库,对提取的人物进行自动化梗概
为什么要进行去重?还不是因为爬虫爬下来的结果有大量的重复的信息,在后期的人名筛选甚至下载来说,我们提前先搞定这个重复的问题,节省工作量。有人提出可以在人名过滤后再去重,我想未尝不是一个好点子,但是HMM-Viterbi算法的复杂度高,这样可能降低后期的效率,提前去重未尝不可。
如图下所示,有很多重复切无用的信息。
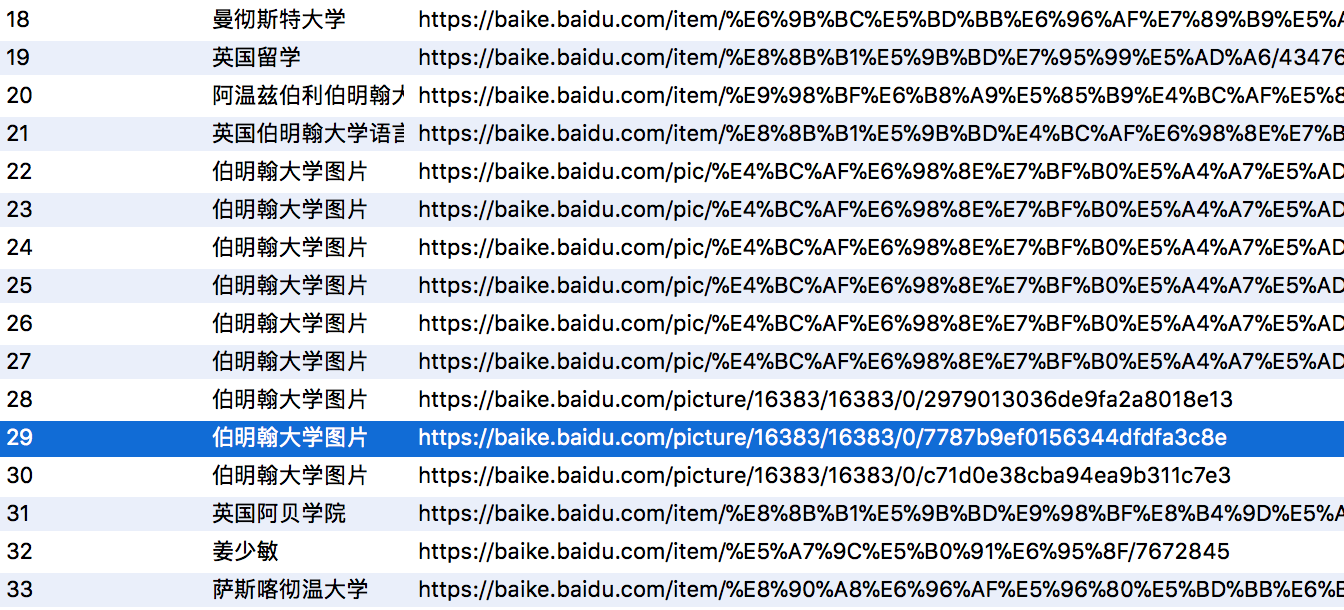
关于去重,很多人第一时间想到了布隆过滤器,但是试问,在仅有不到1000的数据量的数据需要用到吗?本文用pandas自带的去重函数drop_duplictad()去重。如果想了解布隆过滤器,我自己也练手写了一个简单的范例。
首先,将SQL数据库中所有数据作为DataFrame输入到pandas,
然后,对相同名字的内容进行去重,
然后,对相同URL的内容进行去重,
随后,重新建立索引,
最后,将内容输出到新的数据表first_filter上,完成今天的工作。
# coding=utf-8
# python version:2.7
from jpype import *
import pandas as pd
from sqlalchemy import create_engine
import pymysql
reload(sys)
sys.setdefaultencoding('utf-8')
class Filter(object):
def __init__(self):
self.engine = create_engine('mysql+pymysql://root:@localhost:3306/uob?charset=utf8')
def distinct(self):
sql = "SELECT * FROM list;"
allData = pd.read_sql(sql, con=self.engine) # 从抓取过来的数据库读入
allData.drop_duplicates('name', 'first', inplace=True) # 去除重复name
allData.drop_duplicates('url', 'first', inplace=True) # 去除重复url
allData.reset_index(drop=True, inplace=True) # index重新计数
print allData.tail()
allData.to_sql('first_filter', self.engine, if_exists='replace', index=True, index_label='fid') # 输出到新的数据库表first_filter
return allData
if __name__ == "__main__":
obj_filter = Filter()
obj_filter.distinct()
跑完后我们到数据库中看看
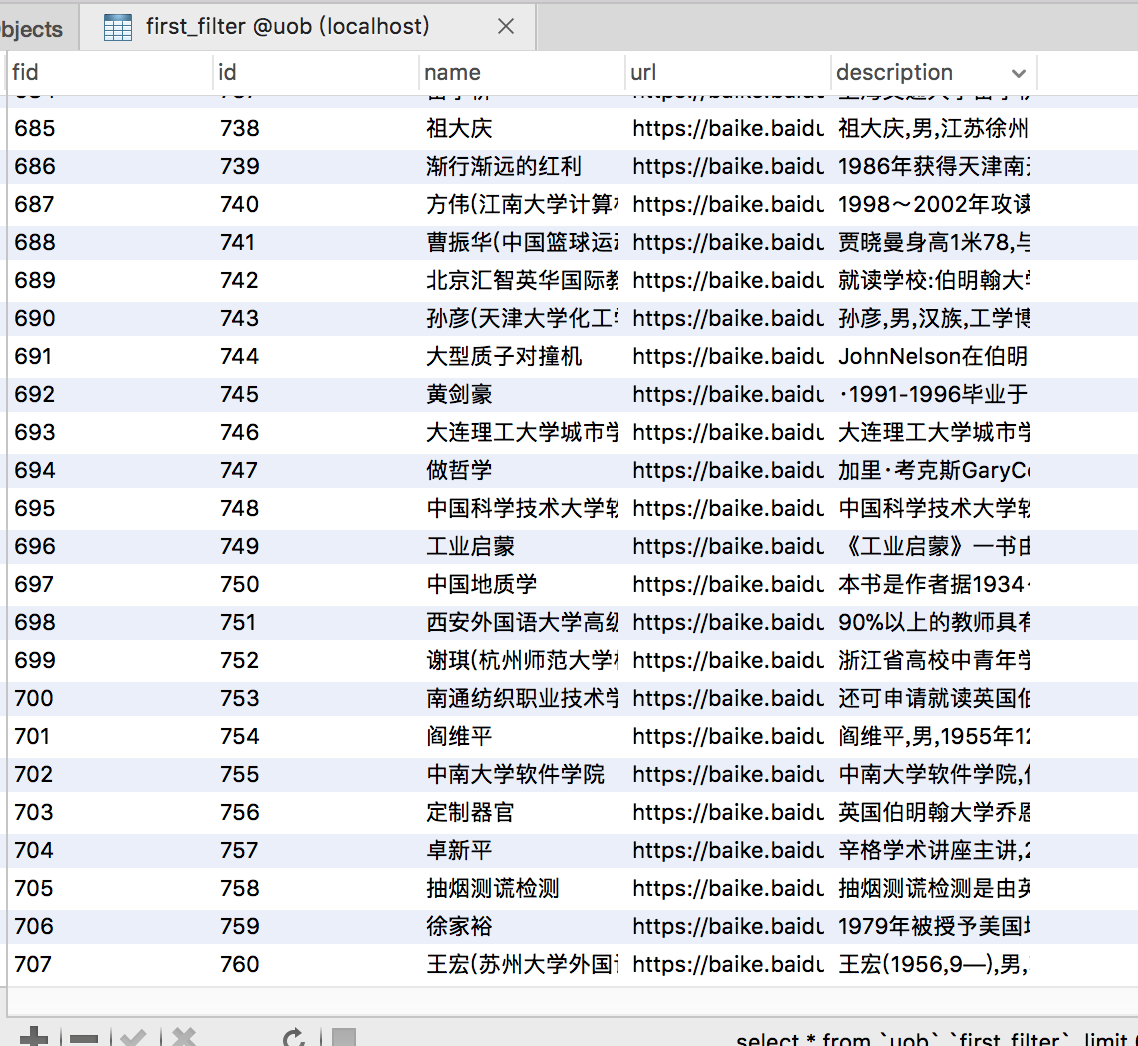
不错,数据量已经下降到了708个,去重工作完成,其实在这期间遇到了很多坑,很多问题,不一一阐述,均为python环境问题。
下集预告:“我是如何收集校友的”之利用基于HMM-Viterbi的HanLP进行人名提取