打开伯明翰大学的百科,发现与某相邻学校相比,中国校友实在太少,可能是校友过于低调。于是萌生一个想法,写一个爬虫找出百度百科里所有与“伯明翰”大学有关的校友,然后自动汇总,生成人物梗概,按照知名度排序。
需求大概就是这样,也就是说,我们需要以下几个模块:
- 爬虫程序——抓取全百度百科与“伯明翰大学”相关的数据
- 数据去重——用pandas去掉抓取相同的URL或相同的名称
- 提取人名——利用HMM-Viterbi进行人名筛选与提取
- 下载器——下载所有数据库中数据清洗过的URL,并存入数据库
- 人物Ranking——按照一定的排名方式,对人物进行知名度排名
- 人物梗概——利用NLP相关库,对提取的人物进行自动化梗概
话不多说,现在开始进行爬虫部分。
爬虫部分分为两类:信息获取器、URL管理器
信息获取器自动抓取百度搜索结果内容,并将其存入URL管理器
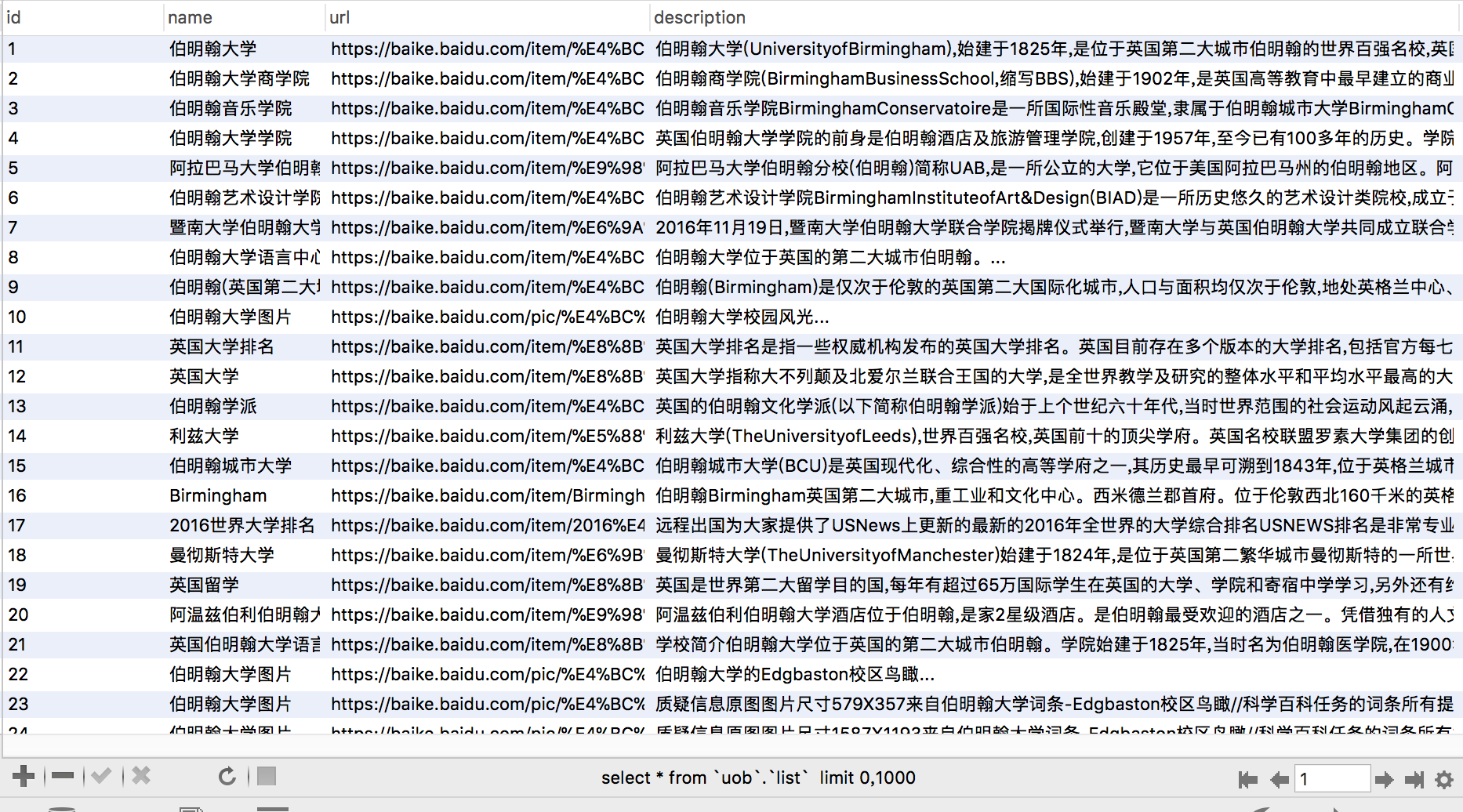
首先建立数据库uob,并且建立一个表明为list的表用于存储百度百科基础数据
SET NAMES utf8;
CREATE TABLE `list` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`url` varchar(255) DEFAULT NULL,
`description` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
spider.py
#coding=utf-8
#python version:2.7
import urllib
import urllib2
import time
from bs4 import BeautifulSoup as BS
from urlmanager import UrlManager
class Spider(object):
def __init__(self):
self.urls = UrlManager() #url管理器
def baidusearch(self,word,page):
baseUrl = 'http://www.baidu.com/s'
data = {'wd': word, 'pn': str(page - 1) + '0', 'tn': 'baidurt', 'ie': 'utf-8', 'bsst': '1'}
data = urllib.urlencode(data)
url = baseUrl + '?' + data
try:
request = urllib2.Request(url)
response = urllib2.urlopen(request)
except urllib2.HttpError, e:
print e.code
exit(0)
except urllib2.URLError, e:
print e.reason
exit(0)
html = response.read()
soup = BS(html, "lxml")
td = soup.find_all(class_='f')
for t in td:
name = t.h3.a.get_text().replace(' ', '').replace(' ', '').replace('\n', '').replace(u'_百度百科','')
# print name
url = t.h3.a['href'].replace(' ', '').replace('\n', '')
# print url
font_str = t.find_all('font', attrs={'size': '-1'})[0].get_text()
start = 0 # 起始
realtime = t.find_all('div', attrs={'class': 'realtime'})
if realtime:
realtime_str = realtime[0].get_text()
start = len(realtime_str)
# print realtime_str
end = font_str.find('...')
# print font_str[start:end+3],'\n'
self.urls.add_new_url(name, url, font_str[start:end+3].replace(' ', '').replace(' ', '').replace('\n', ''))
if __name__=="__main__":
obj_spider = Spider()
for x in range(1,200):
obj_spider.baidusearch('伯明翰大学 site:baike.baidu.com', x)
time.sleep(3)
urlmanager.py
#coding=utf-8
#python version:2.7
import pymysql
class UrlManager(object):
def __init__(self):
self.new_urls = dict() # 待爬取url
self.old_urls = dict() # 已爬取url
self.db = pymysql.connect("localhost", "root", "", "uob" ,use_unicode=True, charset="utf8")
self.cursor = self.db.cursor()
def add_new_url(self, name, url, description): # 向管理器中添加一个新的url
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls[name] = url
sql = u"INSERT INTO list (name, url, description) VALUES (\"" + name + u"\", \"" + url + u"\", \"" + description + u"\");"
print sql
try:
# 执行sql语句
self.cursor.execute(sql)
# 提交到数据库执行
self.db.commit()
# print "success"
except:
# Rollback in case there is any error
self.db.rollback()
print "error"
将数据存入数据库,最后获取信息如下:

明日更新:“我是如何收集校友的”之数据去重